在本文Awk系列内容当中,小编将深入研究Next命令,并了解如何使用它来优化脚本执行,因为该命令对于跳过处理数据时不必要的步骤特别有用。
什么是Next命令?
awk中的Next命令指示它跳过当前行的剩余模式和操作并继续执行下一个输入行,这可以帮助避免执行冗余或不必要的步骤,从而使你的脚本执行更高效。
示例1:根据数量标记商品
首先从一个实际的例子开始,考虑一个名为food_list.txt的文件,其内容如下:
Food List Items No Item_Name Price Quantity 1 Mangoes $3.45 5 2 Apples $2.45 25 3 Pineapples $4.45 55 4 Tomatoes $3.45 25 5 Onions $1.45 15 6 Bananas $3.45 30
考虑运行以下命令,该命令将在每行末尾用(*)符号标记数量小于或等于20的食物:
awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; } $4 > 20 { print $0 ;}' food_list.txt
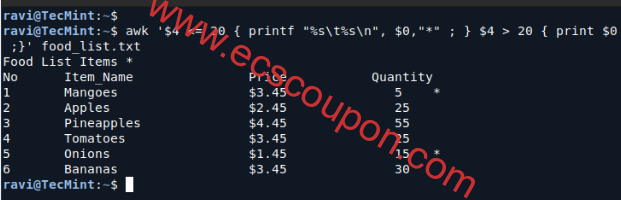
上述命令的实际工作原理表述如下:
- 首先检查每个输入行的数量(第四个字段)是否小于或等于20,如果值满足该条件,则使用表达式一
$4 <= 20打印该值并在末尾用符号(*)标记; - 其次检查每个输入行的第四个字段是否大于20,如果某一行满足条件,则使用表达式二
$4 > 20打印。
但是这里有一个问题,当执行第一个表达式时,我们想要标记的一行会使用{ printf "%s\t%s\n", $0,"**" ; }命令打印;然后在同一步骤中,第二个表达式也会被检查,这就变成了浪费时间的因素。
因此,在打印已使用第一个表达式$4 > 20打印过的标记行之后,无需再次执行第二个表达式。
使用next优化命令
为了解决这个问题,必须使用以下next命令:
awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; next; } $4 > 20 { print $0 ;}' food_list.txt
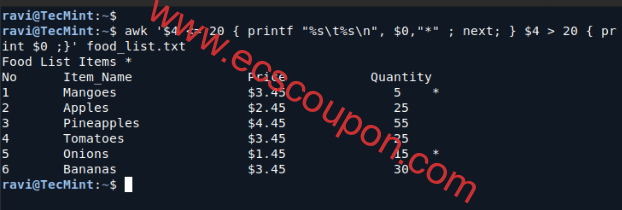
上述命令的工作原理如下:
- 当某一行满足
$4 <= 20条件时,它会打印带有星号的行,然后跳过该行的剩余操作,直接移动到下一行; - 这样可以防止
$4 > 20条件不再检查已经处理过的行。
示例2:过滤和格式化数据
考虑一个包含以下内容的文件data.txt :
ID Name Age Score 1 Alice 30 85 2 Bob 25 90 3 Charlie 35 70 4 David 28 92
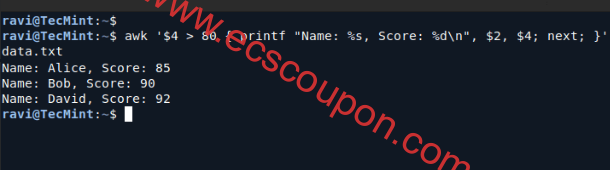
如果只想打印分数高于80的记录并将其格式为“Name: [Name], Score: [Score]“ ,请使用以下命令(建议使用NR > 1跳过标题行):
awk 'NR > 1 && $4 > 80 { printf "Name: %s, Score: %d\n", $2, $4; next; }' data.txt
小结
使用awk中的Next命令是一种有效的方法,可以避免不必要的评估,从而简化数据处理。通过跳过已处理行的其余脚本,这样可以使awk脚本更高效、更快速。